Décodage des données à partir des formats binaires de l'OMM
Objectifs d'apprentissage !
À la fin de cette session pratique, vous serez capable de :
- exécuter un conteneur Docker pour l'image "demo-decode-eccodes-jupyter"
- exécuter les notebooks Jupyter d'exemple pour décoder les données aux formats GRIB2, NetCDF et BUFR
- découvrir d'autres outils pour décoder et visualiser les formats basés sur les tables de codes de l'OMM (TDCF)
Introduction
Les formats binaires de l'OMM tels que BUFR et GRIB sont largement utilisés dans la communauté météorologique pour l'échange de données d'observation et de modèles, et nécessitent généralement des outils spécialisés pour décoder et visualiser les données.
Après avoir téléchargé des données depuis WIS2, vous devrez souvent les décoder pour pouvoir les utiliser davantage.
Diverses bibliothèques de code sont disponibles pour écrire des scripts ou des programmes afin de décoder les formats binaires de l'OMM. Il existe également des outils qui fournissent une interface utilisateur pour décoder et visualiser les données sans avoir besoin d'écrire un programme logiciel.
Dans cette session pratique, nous démontrons comment décoder 3 types de données différents en utilisant un notebook Jupyter :
- GRIB2 contenant des données pour une prévision globale d'ensemble réalisée par le système CMA Global Regional Assimilation PrEdiction System (GRAPES)
- BUFR contenant des données de trajectoire de cyclone tropical issues du système de prévision d'ensemble de l'ECMWF
- NetCDF contenant des données sur les anomalies de température mensuelles
Décodage des données téléchargées dans un notebook Jupyter
Pour démontrer comment vous pouvez décoder les données téléchargées, nous allons démarrer un nouveau conteneur en utilisant l'image 'decode-bufr-jupyter'.
Ce conteneur démarrera un serveur de notebook Jupyter sur votre instance, qui inclut la bibliothèque ecCodes que vous pouvez utiliser pour décoder les données BUFR.
Nous utiliserons les notebooks d'exemple inclus dans ~/exercise-materials/notebook-examples pour décoder les données téléchargées concernant les trajectoires des cyclones.
Pour démarrer le conteneur, utilisez la commande suivante :
docker run -d --name demo-decode-eccodes-jupyter \
-v ~/wis2box-data/downloads:/root/downloads \
-p 8888:8888 \
-e JUPYTER_TOKEN=dataismagic! \
ghcr.io/wmo-im/wmo-im/demo-decode-eccodes-jupyter:latest
Voici une explication de la commande ci-dessus :
docker run -d --name demo-decode-eccodes-jupyterdémarre un nouveau conteneur en mode détaché (-d) et le nommedemo-decode-eccodes-jupyter-v ~/wis2box-data/downloads:/root/downloadsmonte le répertoire~/wis2box-data/downloadsde votre VM dans/root/downloadsdans le conteneur. C'est là que sont stockées les données téléchargées depuis WIS2-p 8888:8888mappe le port 8888 de votre VM au port 8888 dans le conteneur. Cela rend le serveur de notebook Jupyter accessible depuis votre navigateur web à l'adressehttp://YOUR-HOST:8888-e JUPYTER_TOKEN=dataismagic!définit le jeton requis pour accéder au serveur de notebook Jupyter. Vous devrez fournir ce jeton lorsque vous accéderez au serveur depuis votre navigateur webghrc.io/wmo-im/demo-decode-eccodes-jupyter:latestspécifie l'image utilisée par le conteneur, qui inclut les notebooks Jupyter d'exemple utilisés dans les exercices suivants
À propos de l'image demo-decode-eccodes-jupyter
L'image demo-decode-eccodes-jupyter a été développée pour cette formation. Elle utilise une image de base incluant la bibliothèque ecCodes et ajoute un serveur de notebook Jupyter, ainsi que des packages Python pour l'analyse et la visualisation des données.
Le code source de cette image, y compris les notebooks d'exemple, est disponible à wmo-im/demo-decode-eccodes-jupyter.
Une fois le conteneur démarré, vous pouvez accéder au serveur de notebook Jupyter sur votre VM étudiante en naviguant à l'adresse http://YOUR-HOST:8888 dans votre navigateur web.
Vous verrez un écran vous demandant d'entrer un "Mot de passe ou jeton".
Fournissez le jeton dataismagic! pour vous connecter au serveur de notebook Jupyter (sauf si vous avez utilisé un jeton différent dans la commande ci-dessus).
Après votre connexion, vous devriez voir l'écran suivant listant les répertoires dans le conteneur :
Double-cliquez sur le répertoire example-notebooks pour l'ouvrir. Vous devriez voir l'écran suivant listant les notebooks d'exemple :
Vous pouvez maintenant ouvrir les notebooks d'exemple pour décoder les données téléchargées.
Exemple de décodage GRIB2 : Données GEPS de CMA GRAPES
Ouvrez le fichier GRIB2_CMA_global_ensemble_prediction.ipynb dans le répertoire example-notebooks :
Lisez les instructions dans le notebook et exécutez les cellules pour décoder les données téléchargées pour la prévision globale d'ensemble. Exécutez chaque cellule en cliquant dessus puis en cliquant sur le bouton d'exécution dans la barre d'outils ou en appuyant sur Shift+Enter.
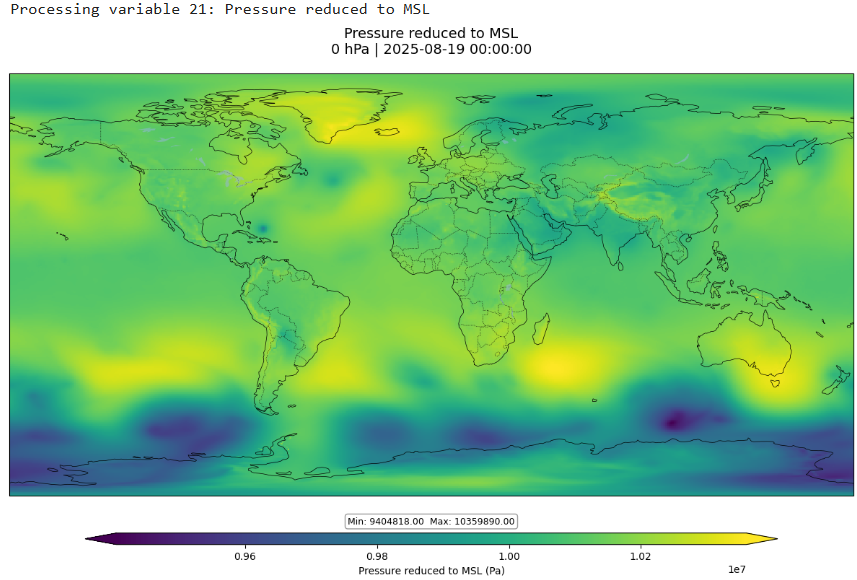
Après avoir exécuté toutes les cellules, vous devriez voir une visualisation pour "Probabilité d'anomalie de température à 850 hPa inférieure à -1,5 écarts-types" :
Question
Comment mettriez-vous à jour la visualisation dans ce notebook pour visualiser un autre message dans le fichier GRIB2 ?
Cliquez pour révéler la réponse
Dans la dernière cellule du notebook, vous verrez le code suivant :
# afficher la visualisation pour le message numéro 8 (Probabilité d'anomalie de température à 850 hPa inférieure à -1,5 écarts-types)
show_map_visualization(grib_file, 8)
Vous pouvez modifier cette ligne ou en ajouter une autre pour visualiser un autre message dans le fichier GRIB2 en changeant le numéro du message :
# afficher la visualisation pour le message numéro 9
show_map_visualization(grib_file, 9)
Ensuite, réexécutez les cellules du notebook pour voir le graphique mis à jour.
Exemple de décodage BUFR : Trajectoires de cyclones tropicaux
Ouvrez le fichier BUFR_tropical_cyclone_track.ipynb dans le répertoire example-notebooks :
Lisez les instructions dans le notebook et exécutez les cellules pour décoder les données téléchargées pour les trajectoires des cyclones tropicaux. Exécutez chaque cellule en cliquant dessus puis en cliquant sur le bouton d'exécution dans la barre d'outils ou en appuyant sur Shift+Enter.
À la fin, vous devriez voir un graphique de la probabilité de trajectoire des cyclones tropicaux :
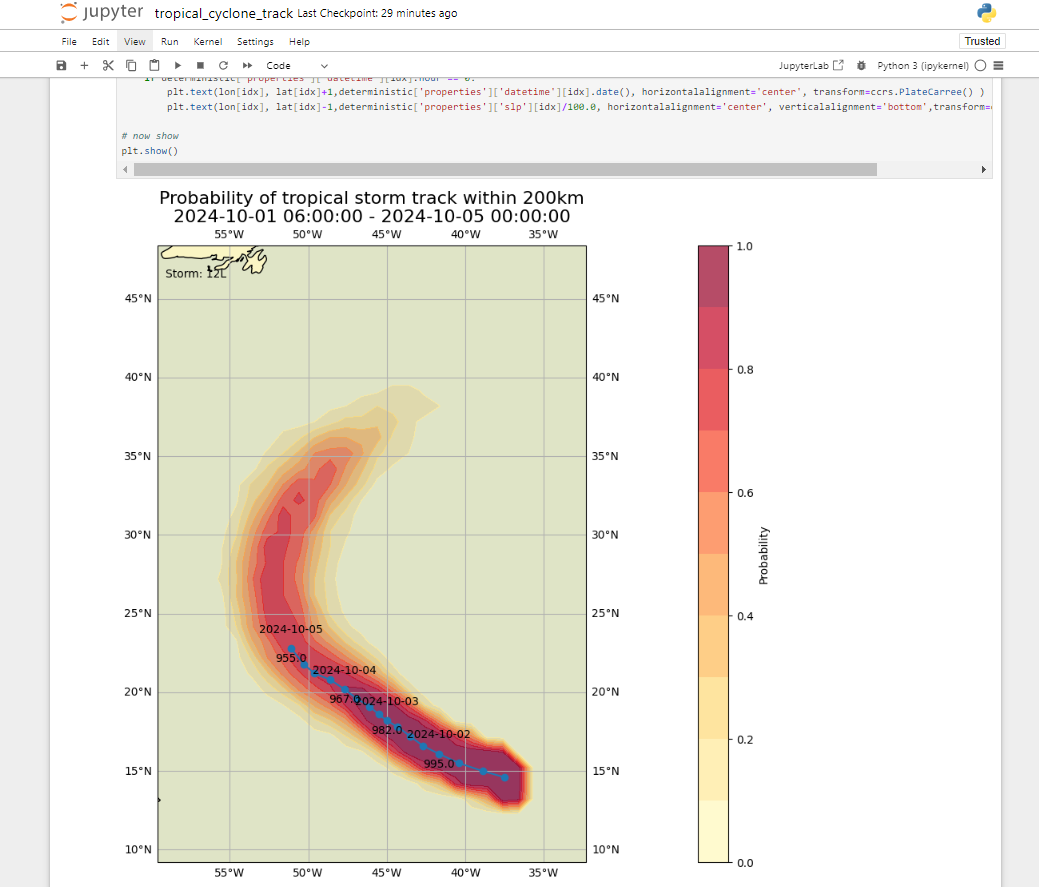
Question
Le résultat affiche la probabilité prévue de trajectoire de tempête tropicale dans un rayon de 200 km. Comment mettriez-vous à jour le notebook pour afficher la probabilité prévue dans un rayon de 300 km ?
Cliquez pour révéler la réponse
Pour mettre à jour le notebook afin d'afficher la probabilité prévue de trajectoire de tempête tropicale dans une distance différente, vous pouvez mettre à jour la variable distance_threshold dans le bloc de code qui calcule la probabilité de trajectoire.
Pour afficher la probabilité prévue dans un rayon de 300 km :
# définir le seuil de distance (en mètres)
distance_threshold = 300000 # 300 km en mètres
Ensuite, réexécutez les cellules du notebook pour voir le graphique mis à jour.
Décodage des données BUFR
L'exercice que vous venez de réaliser a fourni un exemple spécifique de la manière dont vous pouvez décoder les données BUFR en utilisant la bibliothèque ecCodes. Différents types de données peuvent nécessiter des étapes de décodage différentes, et vous devrez peut-être consulter la documentation pour le type de données avec lequel vous travaillez.
Pour plus d'informations, veuillez consulter la documentation ecCodes.
Exemple de décodage NetCDF : Anomalies de température mensuelles
Ouvrez le fichier NetCDF4_monthly_temperature_anomaly.ipynb dans le répertoire example-notebooks :
Lisez les instructions dans le notebook et exécutez les cellules pour décoder les données téléchargées sur les anomalies de température mensuelles. Exécutez chaque cellule en cliquant dessus puis en cliquant sur le bouton d'exécution dans la barre d'outils ou en appuyant sur Shift+Enter.
À la fin, vous devriez voir une carte des anomalies de température :
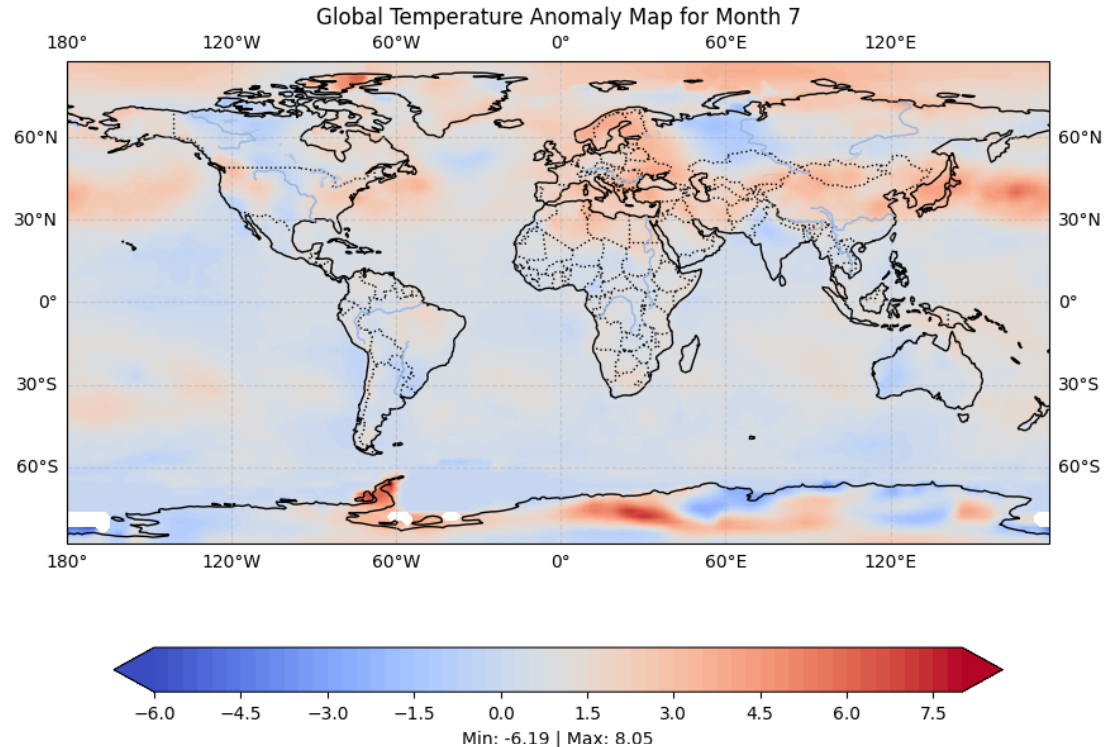
Décodage des données NetCDF
NetCDF est un format flexible qui, dans cet exemple, rapporte les valeurs pour la variable 'anomaly' selon les dimensions 'lat', 'lon'. Différents ensembles de données NetCDF peuvent utiliser des noms de variables et des dimensions différents.
Utilisation d'autres outils pour visualiser et décoder les formats binaires de l'OMM
Les notebooks d'exemple ont démontré comment vous pouvez décoder les formats binaires couramment utilisés de l'OMM en utilisant Python.
Vous pouvez également utiliser d'autres outils pour décoder et visualiser les formats basés sur les tables de codes de l'OMM sans avoir besoin d'écrire de logiciel, tels que :
- Panoply - une application multiplateforme qui trace des tableaux géo-référencés et d'autres tableaux à partir de fichiers NetCDF, HDF, GRIB et autres
- ECMWF Metview - une application météorologique pour l'analyse et la visualisation des données, qui prend en charge les formats GRIB et BUFR
- Integrated Data Viewer (IDV) - un cadre logiciel gratuit basé sur Java pour analyser et visualiser les données géoscientifiques, y compris la prise en charge des formats GRIB et NetCDF
Conclusion
Félicitations !
Au cours de cette session pratique, vous avez appris à :
- exécuter un conteneur Docker pour l'image "demo-decode-eccodes-jupyter"
- exécuter les notebooks Jupyter d'exemple pour décoder les données aux formats GRIB2, NetCDF et BUFR